
📌 本文重點
- 用結構化 trace 做 LLM observability
- 以多模型路由平衡成本、延遲、質量
- 用真實流量自動微調與 A/B 測試
- 建立安全可控的自動優化閉環
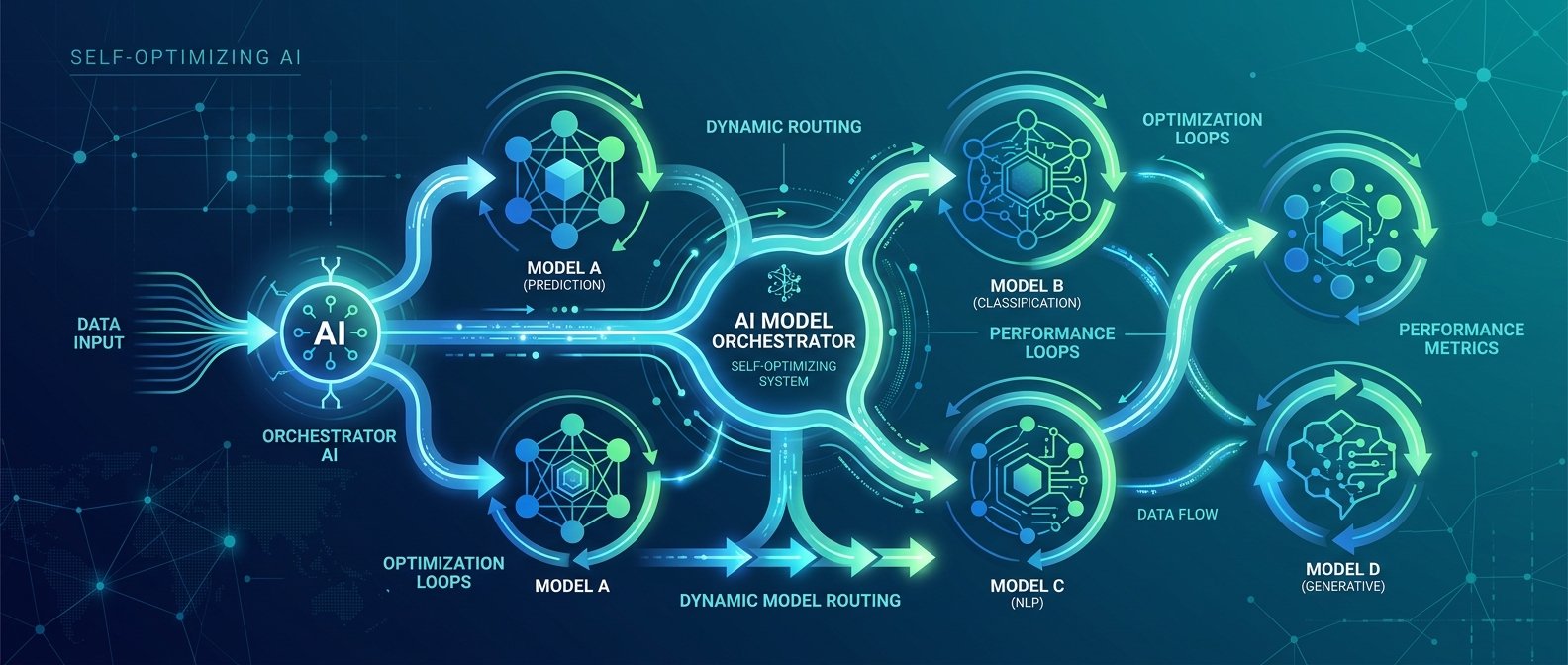
手動挑模型、改 prompt、算預算,做到上線後你會發現:每個路徑都在燒錢,而且調一次就壞一次。這篇的結論很直接:
把「觀測 → 評分 → 路由 → 微調」做成閉環,你的 LLM Stack 會自己變便宜、變準、變穩定,而不是靠工程師加班微調。
下面用一個可落地的架構,示範:
– 要記哪些欄位才能做 LLM observability
– 怎麼設計 線上多模型路由(成本 / 延遲 / 質量三者權衡)
– 用真實流量做 持續微調 + 線上 A/B 測試
– 如何在 安全可控 的前提下讓這個 loop 自動跑
重點說明
1. 觀測是自我優化的資料 API:要記什麼?
你要的不是 log,而是可以訓練 & 決策的 結構化 trace。一筆 LLM 呼叫最少要記:
- 請求層級欄位
trace_id:關聯前後多次呼叫tenant_id/user_id:用於分群 & 權限task_type:如summarize,classify,tagging(路由和微調的最重要欄位)- 模型與成本欄位
model_name:如gpt-4.1,local-7b-v1input_tokens/output_tokenscost_usd:用 provider 單價事後計算latency_ms:end-to-end 延遲- 內容與品質欄位
prompt,completion(支援 PII 遮蔽)quality_score:0–1 或 0–100,可來自:- 人工評分
- 規則(例如是否通過 JSON schema)
LLM-as-judge模型給分
hallucination_flag/safety_flag:是否被檢測為幻覺或違規
💡 關鍵: 把每次 LLM 呼叫記成可查詢的結構化 trace,而不是散亂 log,才能支撐路由、微調與監控三種決策。
這些欄位之後會被用在:
– 自動模型路由(根據歷史質量 + 成本)
– 持續微調(從高信心樣本抽訓練資料)
– 質量監控(模型版本切換時是否退步)
像 Torrix 這類自託管 observability 工具已經把大部分欄位幫你設計好了,你只要在程式碼層接上 proxy 或 SDK 即可。
2. 多模型路由:把成本 / 延遲 / 質量變成可調參數
目標:對每一類請求,自動選擇「在 SLA 內成本最低、且質量不低於門檻」的模型。
常見做法:
1. 用 embedding 對請求做 clustering,找到「相似任務族群」
2. 在每個 cluster 裡統計:每個 model_name 的平均 quality_score, cost_usd, latency_ms
3. 設計一個路由 scoring 函數:
( \text{score} = w_q · q – w_c · \log(1+cost) – w_l · \log(1+latency) )
w_q,w_c,w_l是你可調的權重(例如 B2B 產品就偏質量,內部工具偏成本)
在線上:
– 每次請求先預測 cluster(根據 task_type + embedding)
– 查表得到該 cluster 下每個模型的歷史 score
– 選擇 score 最高模型,加上一點探索策略(epsilon-greedy / UCB)確保新模型有被試用機會
實際好處:
– 把「今天要不要全站切到新模型?」變成連續微調權重的線上學習問題
– 你只要設定業務指標(每月預算、延遲 SLA),Router 會幫你在可接受範圍內壓成本
3. 真實流量驅動的持續微調 + A/B 測試
你不需要標一大堆資料,反而是:
– 利用線上的 quality_score + hallucination_flag 自動篩樣本
– 抽取高信心樣本給 7B/8B 模型微調
– 再把微調後模型放回 Router 做灰度 A/B 測試
做法可以類似 Reddit 那個案例:
– 第 1–3 週:用 GPT-4/5.x 當 teacher,產生高品質標註
– 第 4 週起:用這些資料微調 7B 模型接管特定 task(例如 classify / tagging / summarize)
– 然後透過 Router 把低風險請求(內部標註、非生死決策)逐步導到 7B 模型
💡 關鍵: 把旗艦模型當 teacher,用真實流量訓練 7B/8B 模型,可以做到品質接近但成本只剩個位數百分比。
這樣可以做到「95% 與旗艦模型一致,但成本是 2%」的效果。
實作範例
下面用一個簡化的 Python 範例,示範:
– 接上 Torrix 之類 observability
– 寫一個最小可用的 router
– 基於線上資料做粗略的微調樣本抽取與 A/B 測試策略
1. 設計 Trace 結構與上報(以 Torrix HTTP proxy 為例)
import requests
import time
TORRIX_PROXY_URL = "http://localhost:8787/proxy" # Torrix 的 HTTP proxy
MODELS = {
"fast": "gpt-4o-mini",
"strong": "gpt-4.1",
"cheap_local": "local-7b-v1",
}
def call_llm(model_key: str, prompt: str, task_type: str, meta: dict):
start = time.time()
payload = {
"model": MODELS[model_key],
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.2,
# 重要:附上自訂 metadata,方便 observability / 分群
"metadata": {
"task_type": task_type,
"user_id": meta.get("user_id"),
"tenant_id": meta.get("tenant_id"),
},
}
# 經由 Torrix proxy 轉發,Torrix 會自動記錄 token, cost, latency 等
resp = requests.post(TORRIX_PROXY_URL, json=payload)
resp.raise_for_status()
latency_ms = (time.time() - start) * 1000
data = resp.json()
return {
"completion": data["choices"][0]["message"]["content"],
"latency_ms": latency_ms,
# token / cost 會在 Torrix 裡算,因此這裡只做最小回傳
}
實務上你還會再寫一個 async wrapper,確保不堵住整個 API。
2. 最小可用 Router:基於 task_type + 歷史表現
假設我們在背景 job 定期從 observability DB 撈聚合數據,產生一個 routing table:
# 假設這個表是 batch job 每 5 分鐘更新一次
# 由 observability 系統依 task_type + model 聚合而來
ROUTING_TABLE = {
# task_type: {model_key: {"q": quality, "c": cost, "l": latency_ms}}
"summarize": {
"fast": {"q": 0.92, "c": 0.002, "l": 800},
"strong": {"q": 0.96, "c": 0.01, "l": 1200},
"cheap_local": {"q": 0.90, "c": 0.0004, "l": 950},
},
"classify": {
"fast": {"q": 0.94, "c": 0.002, "l": 700},
"cheap_local": {"q": 0.93, "c": 0.0004, "l": 600},
},
}
# 路由權重:可透過環境變數或管理介面動態調
W_Q = 1.0 # 質量
W_C = 3.0 # 成本敏感度
W_L = 0.5 # 延遲敏感度
def select_model(task_type: str, explore_eps: float = 0.05) -> str:
import math, random
# 探索: 以小機率隨機挑一個模型,給新模型累積資料機會
if random.random() < explore_eps:
return random.choice(list(MODELS.keys()))
stats = ROUTING_TABLE.get(task_type)
if not stats:
# 沒有歷史資料時的 fallback 策略
return "fast" # 或者直接用強模型保守處理
best_score, best_model = -1e9, None
for model_key, v in stats.items():
q, c, l = v["q"], v["c"], v["l"]
score = W_Q * q - W_C * math.log(1 + c) - W_L * math.log(1 + l)
if score > best_score:
best_score, best_model = score, model_key
return best_model or "fast"
def handle_user_request(prompt: str, task_type: str, meta: dict):
model_key = select_model(task_type)
res = call_llm(model_key, prompt, task_type, meta)
return res["completion"]
這樣你的 API 層就已經有一個可學習的 router,之後只要讓 batch job 持續更新 ROUTING_TABLE 即可。
3. 用真實流量抽訓練資料 + A/B 測試策略(偽碼)
下面的 pseudo code 示意:
– 如何從 observability DB 抽出高品質樣本
– 微調本地 7B 模型
– 灰度放量到 router
# 1. 從 trace DB 抽樣本(例如從 Torrix 的 SQLite / exports)
# SELECT prompt, completion, quality_score
# FROM traces
# WHERE task_type = 'classify'
# AND quality_score >= 0.9
# AND hallucination_flag = 0
# AND model_name IN ('gpt-4.1', 'gpt-4.5')
# LIMIT 100_000;
# 2. 整理成 SFT 資料格式
# {"messages": [{"role": "user", "content": prompt},
# {"role": "assistant", "content": completion}]}
# 3. 用你習慣的框架(例如 LlamaFactory / axolotl)做 SFT
# 4. 微調完得到 local-7b-v2,先只在 router 裡給 5% 流量:
# - 在 ROUTING_TABLE 中,classify 下新增 cheap_local_v2 的統計
# - select_model() 的 epsilon-greedy 會開始給它少量流量
# 5. 定期比較:
# - cheap_local_v2 vs cheap_local_v1 vs fast 在同一 task_type 的 quality_score
# - 只有當 v2 的質量穩定 >= v1,才逐步提高 v2 的預設權重
關鍵是:所有決策依賴線上真實質量分數,而不是人工測幾個 prompt。
建議與注意事項
1. 資料隱私:觀測≠把所有東西存一份
- 對
Prompt/Completion要做: - PII 遮蔽(email、電話、身分證、住址)
- 對敏感欄位做 hash / tokenization,只保留足夠做分群的特徵
- 如果你使用像
Torrix這樣的自託管工具: - 優先把 SQLite / volume 放在私有網段,避免開放到公網
- 對離線匯出的 trace 做加密儲存 & 權限控管
實際風險:一旦 trace 被外流,不只是 prompt 洩漏,連你使用了哪些模型、成本結構都會被看光。
2. 評分標準漂移(Evaluation Drift)
當你改了:
– LLM-as-judge 的版本
– 質量打分 rubric(例如原本只看正確性,後來加入安全性)
你歷史的 quality_score 就不再可比。建議:
- 在 trace 裡加上
evaluator_version: evaluator_model_namerubric_version(JSON schema 或 hash)- 做趨勢分析時,同一條圖上只放同
evaluator_version的資料 - 如果要重跑評分,記得把舊分數保留一份,避免回溯分析被污染
3. 模型切換導致行為不穩定
多模型路由會遇到一個常見坑:
– 業務邏輯假設「回傳格式永遠一樣」
– Router 為了省錢,幫你換成另一個模型
– 結果 JSON schema 不穩、排序不同、偶爾講幹話 → 下游全部爆掉
緩解方式:
– 在 observability 層記錄:schema_valid_flag(是否通過 JSON schema 驗證)
– 對格式敏感的任務,在 Router 做:
– 只允許通過 schema 驗證率 > 某門檻的模型
– 或硬性綁定單一模型,先解決穩定性再談成本
– 切換模型時先在只讀場景做 shadow traffic:
– 用新模型跑同一批請求,但不回給使用者,只記分數
– 分數穩定後再逐步放量
4. 安全可控的自動 loop:永遠保留手煞車
即使是自我優化架構,也要留:
– 全局開關:一個環境變數就可以把 router 關掉,全部打到保守模型
– 模型白名單:router 只能從白名單裡選,避免誤打到測試中的模型
– 預算上限:
– observability 層記累計 cost_usd
– 一旦超過日/月預算,強制把高單價模型設為 offline
搭配這些保護,你才敢讓自動 loop 長期自己跑,而不用每天盯帳單。
💡 關鍵: 有全局開關、白名單與預算上限等「手煞車」,才能放心讓自動優化長期在線運行。
總結:
- LLM observability 不是畫漂亮 dashboard,而是提供可訓練 + 可決策的結構化 trace。
- 多模型路由 把成本 / 延遲 / 質量變成可調參數,用線上真實質量分數自動選模型。
- 用真實流量微調小模型 + A/B 測試,可以在特定任務上達到旗艦模型 90–95% 的效能,成本卻只要幾%。
- 同時注意資料隱私、評分標準漂移、模型切換穩定性,並保留手動「手煞車」,你就能讓 LLM Stack 在安全邊界內自己變強、自己變便宜。
🚀 你現在可以做的事
- 列出並實作文中提到的 trace 欄位,接上現有 LLM 呼叫流程
- 寫一個簡單的
select_model(),用歷史quality_score+cost_usd做最小可用路由- 從線上流量中抽樣高
quality_score、低hallucination_flag的請求,整理成 SFT 資料集準備微調小模型
發佈留言