
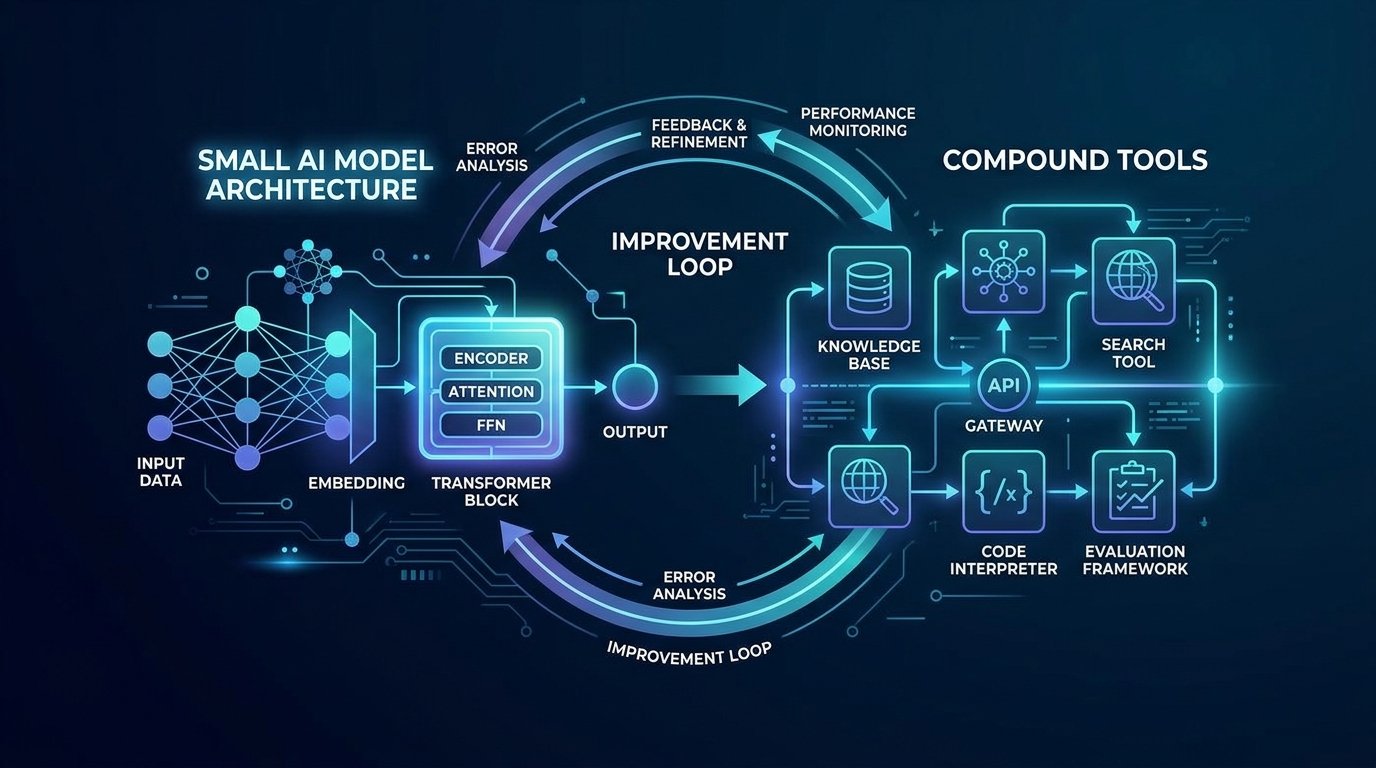
📌 本文重點
- 小模型不適合搭配太多零碎 tools
- 用少量 compound tools 封裝整個工作流
- 加上可控 improvement loop 提升穩定性
- 本地 4B 模型也能跑實用 coding agent
在本地用 4B Gemma 這種小模型帶一個中大型 repo,傳統做法是「LLM + 一堆小工具」:讀檔、寫檔、跑測試、grep 全部拆成獨立 tool。結果大多數人遇到的狀況是:上下文爆炸、工具呼叫瘋狂往返、推理鏈斷裂,小模型最後只會在錯誤訊息上打轉。SmallCode 的重點就是把這些多步操作 封裝成少量高階 compound tools,加上一個可控的 improvement loop,讓 4B 模型也能穩定完成多檔案、反覆修改的任務。
重點說明
1. 為什麼「LLM + 一堆小工具」在小模型上會崩盤
從工程視角,小模型掛點原因其實很單純:
- 上下文爆炸:
- 每呼叫一次
read_file、search、run_tests,LLM 就要重新看到整段對話 + 工具 I/O。 - 小模型 context 小、壓縮能力差,於是早期決策被擠掉,任務計畫完全失憶。
💡 關鍵: 小模型的 context 與壓縮能力有限,多工具頻繁往返會迅速擠掉關鍵決策,導致任務中途失憶。
- 頻繁往返 + 推理鏈斷裂:
- 多工具設計變成:
LLM → read_file → 回答 → write_file → 回答 → run_tests ... -
每一步都要模型自己想「下一步該用什麼工具」,對小模型來說元認知成本太高,很容易在第 3、4 步就跑偏。
-
錯誤訊息解析太細碎:
- 錯誤訊息來了:
run_tests→ 報一堆 stacktrace → LLM 要自己決定要再read_file哪幾個檔案。 - 4B 模型常常讀錯檔或只讀到片段,最後修 bug 幻覺化。
SmallCode 的做法是:把「讀檔 → 修改 → 測試」這個典型工作流視為一個原子操作,交給 compound tool 內部處理,LLM 只需要決定「要不要再試一次?」。
2. Compound Tools:把多步工作流變成一個 API
設計思路可以簡化成三件事:
- 把多步操作拉到工具內執行
- 典型例子:
edit_and_test:- 根據指定 glob pattern 讀檔
- 在本地套用 LLM patch(或簡單模板)
- 寫回檔案
- 跑
pytest/npm test,收集輸出
-
對 LLM 而言,這整件事就是 一次工具呼叫 + 一個結構化結果。
-
清楚定義輸入 / 輸出 Schema
輸入 Schema(JSON Schema 或 Pydantic)範例:
python
class EditAndTestInput(BaseModel):
goal: str # 自然語言:『讓 tests/test_api.py 全部通過』
target_files: List[str] # ['src/api.py', 'tests/test_api.py']
test_command: str = "pytest -q"
max_edits: int = 3
輸出 Schema:
“`python
class EditSummary(BaseModel):
file: str
diff: str # unified diff
class EditAndTestOutput(BaseModel):
success: bool
edits: List[EditSummary]
test_output: str
error_summary: Optional[str]
“`
重點是讓小模型只要關注:有沒有成功?改了哪些檔?錯在哪裡?
- 在一次工具呼叫中完成工作流
Tool handler(Python 假想範例):
“`python
def edit_and_test_tool(payload: EditAndTestInput) -> EditAndTestOutput:
# 1. 收斂上下文:只讀需要的檔案內容
files = {f: Path(f).read_text() for f in payload.target_files}
# 2. 呼叫同一個或更小的 LLM 產生 patch(可本地或子進程)
patch = call_llm_generate_patch(goal=payload.goal, files=files)
edits = apply_patch_to_files(patch)
# 3. 寫回檔案
for e in edits:
Path(e.file).write_text(e.new_content)
# 4. 跑測試
ok, test_output = run_command(payload.test_command)
return EditAndTestOutput(
success=ok,
edits=[
EditSummary(file=e.file, diff=e.diff)
for e in edits
],
test_output=test_output,
error_summary=None if ok else summarize_test_output(test_output),
)
“`
好處:主 agent 模型只要發出一個 edit_and_test 呼叫,不用自己 orchestrate read_file、write_file、run_tests,大幅降低 思考步數 和 context 髒亂度。
3. Improvement Loop:可控的自我改進迴圈
SmallCode 成效好的關鍵是:讓 retry 變成一級公民,而不是「失敗就結束」。
- 失敗偵測策略
- 以 compound tool 的輸出為主,不讓模型自己猜:
success == Falsetest_output中出現關鍵字(FAILED、Traceback、AssertionError)
-
這樣 loop controller 可以用硬邏輯判斷下一步,不依賴 LLM 理解每一行 stacktrace。
-
重試策略
簡單可用的架構:
“`python
MAX_ATTEMPTS = 5
for attempt in range(1, MAX_ATTEMPTS + 1):
tool_result = edit_and_test_tool(input_payload)
if tool_result.success:
break
feedback = build_feedback_prompt(tool_result)
input_payload.goal = feedback # 將錯誤摘要回餵給模型
“`
build_feedback_prompt 可以把 error_summary + 失敗測試名稱打包,讓下一輪 LLM 更聚焦。
- 避免無限 loop 的做法
- 硬限制:
MAX_ATTEMPTS、最大 wall time。 - 檢查 edits 是否變化:若連續兩次 diff 幾乎一樣(甚至相同 hash),就早停。
- error signature 去重:同一個 assertion / stacktrace 重複出現 N 次就停止,標記為「需要人介入」。
這樣,4B 模型只要能理解「這次錯在哪裡、我還有幾次機會」,就足以在迴圈中持續收斂。
4. 在本地 4B 模型上的部署實務
以 Gemma 2 4B 為例,用 llama.cpp / Ollama 都可以吃得很順,但細節會影響體驗:
- 記憶體與延遲粗估
- 4B
Q4_K_M:VRAM 約 3–4 GB;Q6大概 5–6 GB。 - context 8k、推理 1 token ≈ 10–40 ms,視 CPU/GPU 而定。
- agent 架構推薦:主模型用中量化(Q4/Q5)+ MTP(若硬體支援),工具內部幫忙 patch 的模型可以更小或更低位元。
💡 關鍵: Gemma 2 4B 在 Q4 量化、約 3–4 GB VRAM 和 8k context 下即可順暢運行,適合作為本地實用 coding agent 的基礎。
llama.cpp整合範例
bash
# 轉 GGUF 後
./llama-cli \
-m gemma-2-4b-q4_k_m.gguf \
-c 8192 \
-ngl 35 \ # offload 到 GPU layer 數
--temp 0.2 \
--top-p 0.9
在你的 agent server(Python)裡包一層簡單的 HTTP:
“`python
from llama_cpp import Llama
llm = Llama(model_path=”gemma-2-4b-q4_k_m.gguf”, n_ctx=8192)
def chat(messages):
return llm.create_chat_completion(
messages=messages,
tools=TOOLS_SCHEMA, # compound tools 定義
)
“`
- Ollama 整合範例
yaml
# Modelfile
FROM gemma2:4b
PARAMETER temperature 0.2
PARAMETER num_ctx 8192
Python 呼叫:
“`python
import requests, json
def ollama_chat(messages, tools=None):
payload = {“model”: “gemma2-4b”, “messages”: messages}
if tools:
payload[“tools”] = tools
r = requests.post(“http://localhost:11434/api/chat”, json=payload)
return r.json()
“`
注意:不要貪心開太大 context,4B 小模型在 16k context 上的品質掉得很明顯,8k 左右通常較穩定。
實作範例:簡化版 SmallCode 架構
以下是一個「可以直接改造」的最小可行架構:
# 1. 定義 compound tools
TOOLS_SCHEMA = [
{
"type": "function",
"function": {
"name": "edit_and_test",
"description": "Edit target files to satisfy goal and run tests.",
"parameters": EditAndTestInput.model_json_schema(),
},
},
]
# 2. Agent 迴圈
def coding_agent(task_description: str):
messages = [
{"role": "system", "content": "你是嚴謹的資深工程師,專注讓測試通過。"},
{"role": "user", "content": task_description},
]
for attempt in range(1, 6):
resp = ollama_chat(messages, tools=TOOLS_SCHEMA)
choice = resp["message"]
if "tool_calls" not in choice:
# 當成總結
return choice["content"]
for tool_call in choice["tool_calls"]:
if tool_call["function"]["name"] == "edit_and_test":
args = json.loads(tool_call["function"]["arguments"])
result = edit_and_test_tool(EditAndTestInput(**args))
# 記錄 tool 結果
messages.append({
"role": "tool",
"name": "edit_and_test",
"content": result.model_dump_json(),
})
if result.success:
messages.append({
"role": "user",
"content": "測試已通過,請簡要總結你做了什麼修改。",
})
final = ollama_chat(messages)
return final["message"]["content"]
return "多次嘗試仍未通過測試,請人工檢查。"
實際好處:
– 你不需要讓 4B 模型自己 orchestrate 所有 file ops,只決定「目標」和「是否繼續嘗試」。
– 迴圈與成功判斷在 host 程式碼內可觀測、可監控,易於 debug。
建議與注意事項
- tool 太細 vs 太粗的 trade-off
- 太細:
read_file、write_file、run_tests分開 → 小模型迷路。 - 太粗:一個 tool 內藏太多隱含狀態 → 工具結果難以解釋與監控。
-
建議:以「一次迴圈可解決的一個明確目標」為單位設計 compound tool,例如:
edit_and_test_suite、add_feature_and_generate_tests。 -
錯誤訊息解析策略
- 不要把整個 test log 丟給小模型,先在 host 端做:
- 只保留最後一個錯誤 block
- 摘要檔名、行號、錯誤訊息
-
這樣可以避免 4B 模型被 1k tokens 的 noisy log 淹沒。
-
測試覆蓋率不足導致的幻覺修 bug
- 如果只有 1–2 個測試,小模型會傾向「只讓這兩個測試過」而破壞其他邏輯。
-
實務上:
- 優先在 agent pipeline 前補上最小必要測試
- 或在 tool 裡檢查 diff 是否只動到相關檔案/區塊(heuristic)。
-
如何監控與記錄 agent 決策
- 每一次迴圈記錄:
- 使用的 tool 名稱 + 輸入參數
- diff 摘要(檔名、行數、行數變化量)
- test command 與結果(pass/fail、耗時)
- 建議:
text
logs/
session-2025-05-21T12-34-56Z/
step-01-request.json
step-01-edit_and_test-input.json
step-01-edit_and_test-output.json
step-01-diff.patch
之後你可以回放整個 session,分析為什麼某一輪跑偏,進而調整 tool schema 或 system prompt。
總結:如果你想在本地 4B 模型上做實用的 coding agent,不要再堆滿十幾個零碎 tools。把關鍵工作流收斂成少量 compound tools,加上一個明確可控的 improvement loop,再配合 llama.cpp / Ollama 的輕量部署,就能把原本只敢交給 GPT-級別模型的任務,下放到可自託管的小模型上。
🚀 你現在可以做的事
- 在現有 agent 專案中,把零碎的
read_file/write_file/run_tests整合成一個edit_and_testcompound tool- 用 Gemma 2 4B + Ollama 或
llama.cpp在本地啟一個 8k context、Q4 量化的測試環境- 為你的 repo 實作一個最小版 improvement loop,限制
MAX_ATTEMPTS並記錄每次 diff 與測試結果