
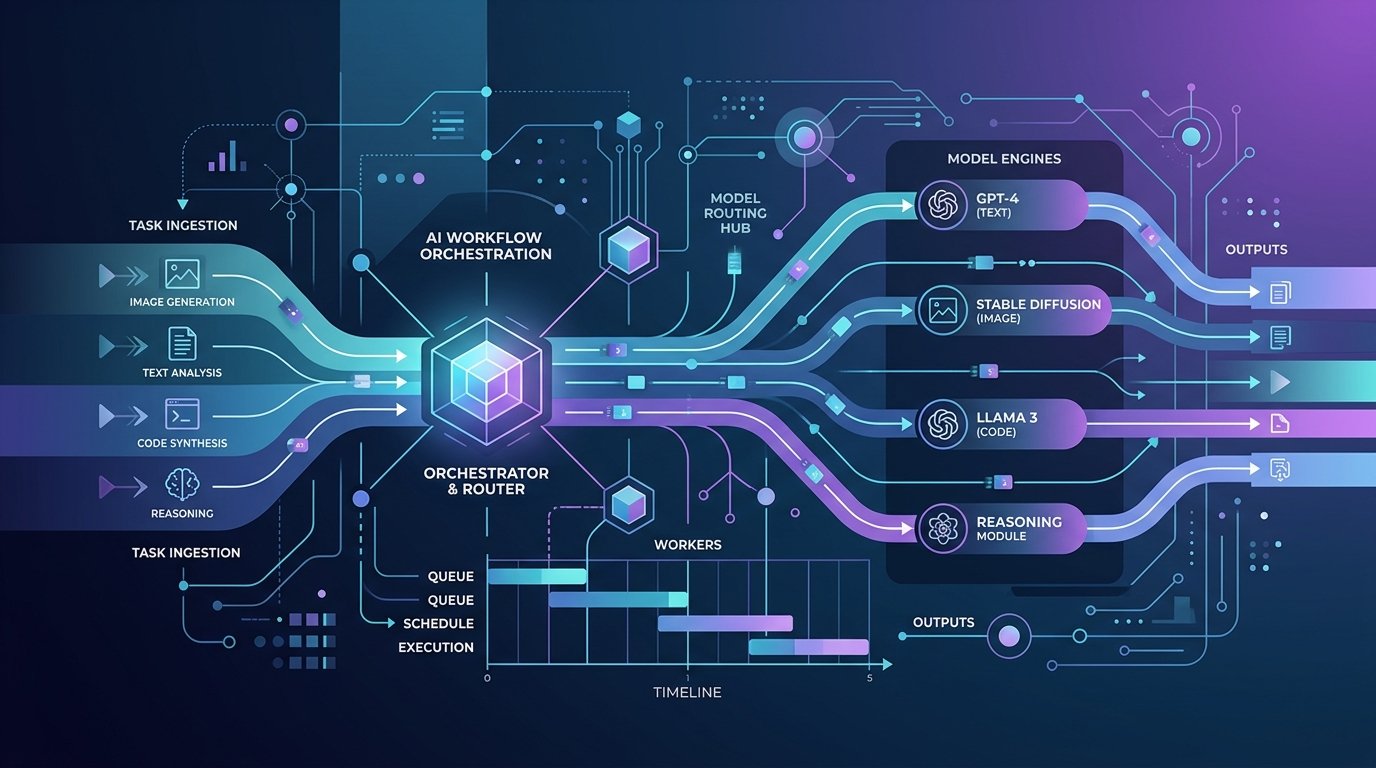
一句話先說清楚:Mellum2 是一顆專門幫你「排班、調度」其他大模型和工具的小模型,用來做 routing、任務拆解與工具選擇,讓 AI 工作流更便宜、更穩定。
📌 本文重點
- Mellum2 是專門做「決策與調度」的小模型
- 適合負責 routing、任務拆解和工具選擇
- 能幫多模型、多工具的工作流壓成本、提穩定度
- 很適合拿來做 AI agent 的中樞大腦
官方介紹與原始碼:https://blog.jetbrains.com/ai/2026/06/mellum2-goes-open-source-a-fast-model-for-ai-workflows/
核心功能:先讓 Mellum2 當你的「AI 排班主管」
1. 低延遲的小模型,適合做決策層
Mellum2 本身不是 GPT-4o 那種萬能助手,它更像是負責「決定下一步要幹嘛」的主管:
- 模型體積小、推理快,適合放在整個 pipeline 的最前面或中間層
- 每次呼叫成本低,很適合頻繁決策:用哪個工具?要不要再拆一步?該重試還是直接回覆?
💡 關鍵: 把高頻率、邏輯性的「決定怎麼做」交給便宜小模型,昂貴大模型只負責「實際做」,能讓整體成本大幅下降。
你可以怎麼用?
- 把「判斷任務類型 → 選模型 → 選工具」這段邏輯,從你程式碼的 if-else 搬到 Mellum2
- 所有複雜 workflow 的分支規則,盡量改成 prompt + Mellum2 來決定,減少硬寫規則
2. 多步推理:讓它負責拆任務、串工具
JetBrains 把 Mellum2 設計成適合多步推理(multi-step reasoning)的模型,也就是它擅長做:
- 任務拆解:把「寫一份技術規格書」拆成「補資料 → 查 API → 產出草稿 → 校對」
- 步驟規劃:決定每一步要用哪支工具或哪個 LLM
- 狀態更新:根據上一個工具的輸出,動態調整下一步
你可以怎麼用?
- 把你現有的工具(爬網頁、查資料庫、呼叫商用 LLM)列成一張「工具清單」給 Mellum2
- 請 Mellum2 每次都輸出「下一步要用的工具 + 工具參數」,你的程式只負責照做
3. Routing + 工具選擇:讓 GPT、Claude、開源 LLM 都變成「插件」
Mellum2 最實用的角色,就是做模型路由(model routing)和工具選擇(tool selection):
- 你可以在後面接:GPT-4.1、Claude 3.7、Llama、Qwen 等
- Mellum2 根據需求幫你選:「這題要便宜模型」還是「這題要高準確度」
💡 關鍵: 當你同時使用多個 LLM 供應商時,用 Mellum2 做路由,可以在「品質不明顯下降」的前提下,讓大量請求自動落在較便宜的模型上。
可以這樣設計一個簡單策略
- 查資料類問題 → 用便宜/開源 LLM + 搜尋工具
- 寫程式、寫長文 → 用 GPT-4.1 或 Claude 3.7
- 簡單 Q&A → 用本地 LLM,節省 API 費用
你的程式不用管細節,只要:
- 收到使用者請求
- 把請求 + 目前可用模型列表丟給 Mellum2
- 照 Mellum2 的輸出去呼叫對應模型
適合誰用:三種典型場景
1. 你在做「AI 助手」或 Agent 系統
如果你在做:
- 產品內建 AI 助手(客服、知識庫問答)
- 自動化 Agent(幫你查資料、寫報告)
問題通常會是:
- 使用者問題差異很大,單一模型不是太貴就是太弱
- 工具越加越多,判斷流程 if-else 爆炸
Mellum2 能幫你:
- 把「選模型、選工具、拆步驟」集中到一顆小模型管理
- 你只要維護工具清單和觀察 Mellum2 的決策是否合理
可以實作的行動:
- 先挑三個最常用工具:RAG 搜尋、商用 LLM、本地 LLM
- 寫一個 Mellum2 prompt,要求它根據需求選 1-3 個步驟完成任務
2. 你有多個 LLM 供應商,要壓成本又要穩定
典型狀況:
- 公司已經有 OpenAI 帳號,也在測 Claude,還有自家的 vLLM 服務
- 主管希望「多用便宜模型,但品質不能掉太多」
Mellum2 的用法:
- 給它模型清單:
gpt-4.1: 高成本、高品質gpt-4o-mini: 中等品質、便宜local-llama: 最便宜、品質較不穩- 附帶一些示例(few-shot),教 Mellum2 什麼情境選哪個
💡 關鍵: 先在開發環境裡讓所有請求經過 Mellum2 路由,實際觀察不同任務落在昂貴與便宜模型的比例,再調整規則,比一開始就死寫策略安全得多。
可以實作的行動:
- 先在開發環境改成「所有請求都要經過 Mellum2 路由」
- 觀察一週:不同任務下,商用 LLM 和本地 LLM 的占比、成本變化
3. 你要做「穩定的 AI Pipeline」而不是單次聊天
像是:
- 每天自動爬資料 → 摘要 → 存進 Notion
- 每次有 Pull Request → 產生 code review 建議
這種 Pipeline 常見問題:
- 某個 LLM 偶爾出錯,整條流程掛掉
- 你需要 fallback 策略:失敗就換模型、換 prompt、換工具
Mellum2 可以:
- 監看每一步工具回傳結果(成功 / 失敗 / 異常訊息)
- 根據結果決定下一步:
- 重試同一步驟
- 改用另外一個模型
- 回報錯誤給人類
可以實作的行動:
- 把 Pipeline 的每一步都包成「工具」
- 每一步的錯誤,也當作輸入回饋給 Mellum2,讓它決定接下來的補救策略
怎麼開始:從安裝到最小可行範例
以下流程以「你會用 Docker 或 Python,且已經有至少一個 LLM API(OpenAI / Anthropic / 本地 vLLM)」為前提。
1. 安裝 Mellum2:Docker 或程式庫二選一
先到官方部落格或 Repo:https://blog.jetbrains.com/ai/2026/06/mellum2-goes-open-source-a-fast-model-for-ai-workflows/
選項 A:用 Docker 跑起 Mellum2 服務
- 安裝 Docker / Docker Compose
- 拉取 Mellum2 映像(以官方 README 為準,示意):
bash
docker pull jetbrains/mellum2:latest
- 啟動服務(假設開在 8000 port):
bash
docker run -p 8000:8000 jetbrains/mellum2:latest
- 用
curl測試:
bash
curl -X POST http://localhost:8000/infer \
-H "Content-Type: application/json" \
-d '{"input": "你是任務規劃器,請幫我決定下一步要用什麼工具"}'
適合: 想先用 HTTP API 串現有後端的人。
選項 B:在程式裡直接呼叫 Mellum2
如果官方有 Python 套件(假設為 mellum2):
pip install mellum2
簡單測試:
from mellum2 import MellumClient
client = MellumClient(base_url="http://localhost:8000") # 或直接用雲端端點
resp = client.infer("你是任務規劃器,收到任務後要輸出下一步計畫")
print(resp)
適合: 你準備把 Mellum2 深度嵌到自家服務裡。
2. 示範:Mellum2 做 Router + 任務規劃的最小 workflow
下面是一個最小可行例子:
- 你有兩個底層 LLM:
gpt-4.1(高品質)local-llama(便宜)- 有一個簡單工具:
web_search(用來查網路) - 目標:收到使用者問題,由 Mellum2 決定:
- 要不要先搜尋
- 要用哪個模型產生最終答案
Step 1:定義給 Mellum2 的「工具/模型清單」
TOOLS = [
{
"name": "web_search",
"type": "tool",
"desc": "適合需要即時或最新資訊的問題,例如股票、新聞、價格。"
},
]
MODELS = [
{
"name": "gpt-4.1",
"cost": "high",
"quality": "best",
"desc": "用在需要高準確度、長文、程式碼的回答。"
},
{
"name": "local-llama",
"cost": "low",
"quality": "medium",
"desc": "用在一般聊天、簡單問答。"
}
]
Step 2:設計 Mellum2 Prompt,請它輸出「計畫 JSON」
SYSTEM_PROMPT = """
你是 AI 工作流調度器,負責:
1. 判斷使用者需求
2. 決定是否要先使用工具
3. 選擇要使用的底層 LLM
請只輸出 JSON,不要多餘文字,格式:
{
"steps": [
{"action": "tool" | "model", "name": "...", "input_from": "user" | "prev_result"}
]
}
可用工具:
{tools}
可用模型:
{models}
""".format(tools=TOOLS, models=MODELS)
Step 3:呼叫 Mellum2,拿到決策後執行
import json
from mellum2 import MellumClient
mellum = MellumClient(base_url="http://localhost:8000")
user_query = "幫我分析最近 NVIDIA 股價的變化,順便預測未來一季可能走勢。"
planning_prompt = SYSTEM_PROMPT + f"\n使用者問題:{user_query}"
plan_resp = mellum.infer(planning_prompt)
plan = json.loads(plan_resp["text"]) # 依實際回傳欄位調整
result_cache = None
for step in plan["steps"]:
if step["action"] == "tool" and step["name"] == "web_search":
query = user_query if step["input_from"] == "user" else result_cache
result_cache = call_web_search(query) # 這是你自己實作的搜尋功能
if step["action"] == "model":
model_name = step["name"]
model_input = user_query if step["input_from"] == "user" else result_cache
result_cache = call_llm(model_name, model_input) # 依照名稱選擇 gpt / llama
print("最終回答:", result_cache)
這樣,你已經有了一個:
- Mellum2 做「任務規劃 + 模型/工具選擇」
- 後端只負責執行計畫的最小可行 workflow
接下來要擴充,只要:
- 在
TOOLS/MODELS裡再加項目 - 用 few-shot 例子微調 Mellum2 的決策邏輯
Mellum2 在你的工具箱裡,扮演什麼角色?
如果從「AI 工作流」角度看,目前常見的組合大致是:
| 名稱 | 核心功能 | 免費方案 | 適合誰 |
|---|---|---|---|
| Mellum2 | 工作流調度、routing、任務拆解 | 開源可自架 | 想自己組 AI pipeline,需要細控成本與流程的人 |
| OpenAI GPT | 高品質通用 LLM | 有免費額度 | 需要高品質輸出、但不想自己訓練模型的人 |
| Claude / Sonnet | 對話 & 程式能力強的商用 LLM | 有試用 | 重度寫作、程式輔助、長上下文需求 |
| 本地 LLM(Llama/Qwen) | 私有部署、低成本推理 | 視模型而定 | 在意隱私或有大批量推理需求的團隊 |
Mellum2 並不是另一個「跟你聊天的模型」,而是用來把上面這些工具串起來、排程好、決定誰在什麼時候上場的小模型。
你可以從一個最小的 routing + 任務規劃範例開始,先讓 Mellum2 管理兩個模型、一支工具,跑順了再往外擴。
🚀 你現在可以做的事
- 打開官方文章與 Repo,確認 Mellum2 的最新安裝方式與 API 規格:https://blog.jetbrains.com/ai/2026/06/mellum2-goes-open-source-a-fast-model-for-ai-workflows/
- 在你的專案裡挑出兩個 LLM + 一個工具,依文中範例實作一個最小 routing workflow
- 收集一週實際流量,觀察 Mellum2 的模型選擇與成本變化,再用 few-shot 逐步調整決策邏輯